A common misconception in epidemiology is that random intercepts can fix confounding. This post demonstrates through simulation that this is not the case, and provides guidance on when random intercepts should be used.
Mixed effects models are a crucial tool in the modern epidemiologist’s toolbox. They allow for the estimation of both fixed and random effects, which can help to account for the correlation structure in the data. However, it is a common misconception that random intercepts can fix epidemiological confounding.
This post will use lme4 and rstanarm to demonstrate that this is not the case, and then provide some guidance on how to properly adjust for confounding and when random intercepts should be used.
A common aim in the field of epidemiology is to precisely measure the association between two variables, typically referred to as the outcome and exposure. The estimation of this association is typically biased due to confounders. A confounder is defined as an independent variable that is associated with both the outcome and the exposure. The presence of a confounder can lead to biased estimates of the exposure-outcome association, unless it is appropriately taken into account.
Mathematical framework
Consider the following simple linear regression model:
where \(Y_i\) is the outcome, \(X_i\) is the exposure, and \(\epsilon_i\) is the error term. The parameter of interest is \(\beta_1\), which represents the association between the exposure and the outcome.
Now, if there is a confounder \(C_i\) that is associated with both \(X\) and \(Y\), then the estimate of \(\beta_1\) in Formula 1 will be biased. An unbiased estimate of \(\beta_1\) can be obtained by adjusting for the confounder:
A more complex situation occurs when there are multiple clusters in the data, such as patients within hospitals, or students within schools. In this case, a random intercept can be added to the model to account for the correlation within clusters:
where \(u_{0j} \sim N(0, \sigma_u^2)\) represents the random intercept for cluster \(j\), and \(\epsilon_{ij} \sim N(0, \sigma_e^2)\) represents the individual-level error term.
The key question is: Does the random intercept \(u_{0j}\) adequately control for cluster-level confounding?
Simulation study
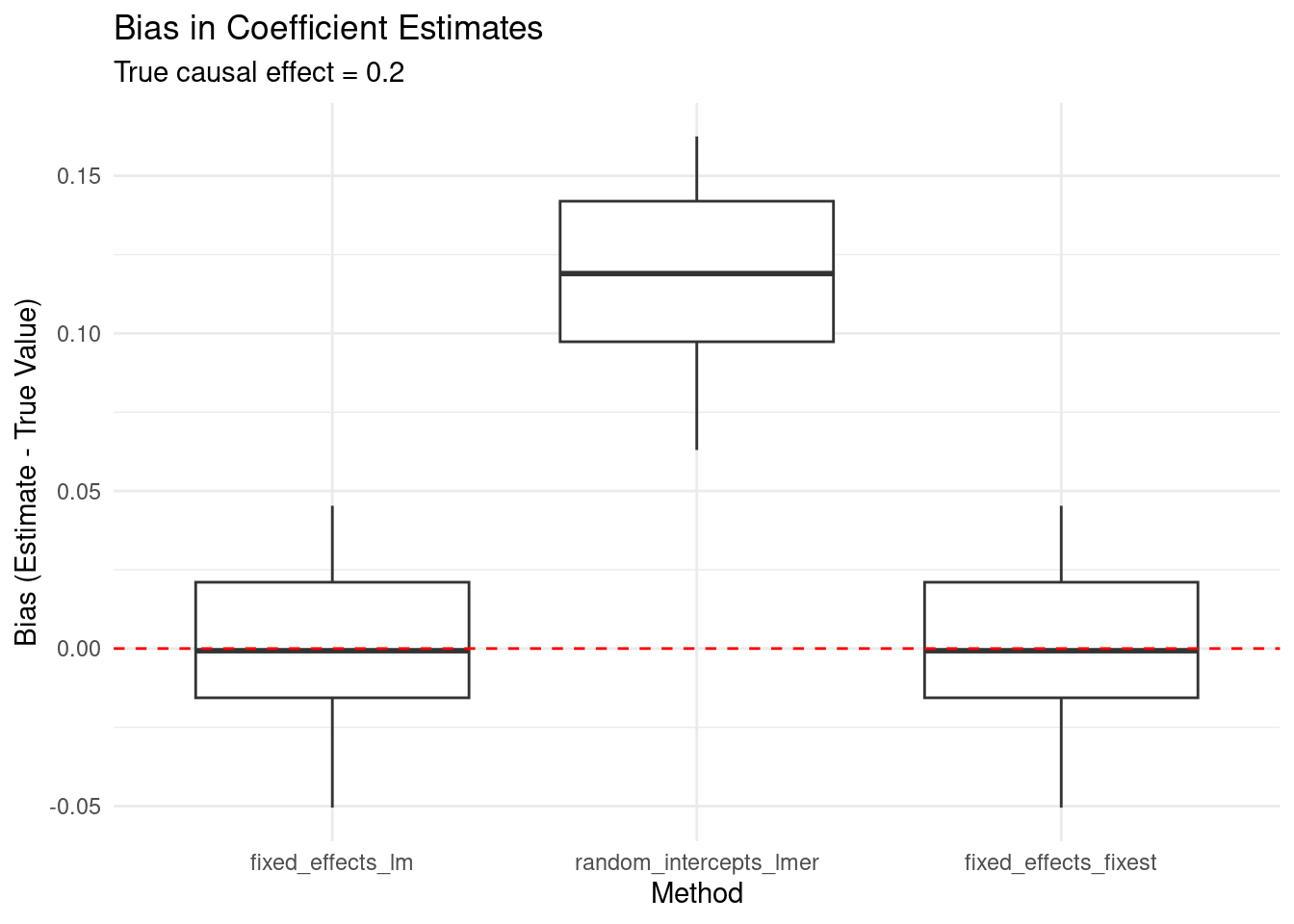
Let’s demonstrate through simulation that random intercepts do not fix confounding when the confounder varies at the cluster level.
# Load required librarieslibrary(data.table)library(ggplot2)library(magrittr)library(lme4)library(fixest)set.seed(123)# Parametersn_clusters <-500cluster_size <-20n <- n_clusters * cluster_size# Cluster IDscluster_id <-rep(1:n_clusters, each = cluster_size)# We'll run multiple simulations to get stable resultsraw <-vector("list", length =20)for(i inseq_along(raw)){cat("Simulation", i, "\n")# Strong cluster-level confounder U_cluster <-rnorm(n_clusters, mean =0, sd =1) U <- U_cluster[cluster_id]# Simulate exposure with strong effect from U# Weak individual-level noise X <-0.8* U +rnorm(n, mean =0, sd =0.5)# Simulate outcome with strong U effect and weak X effect# TRUE causal effect of X on Y is 0.2 Y <-1.5* U +0.2* X +rnorm(n, mean =0, sd =1)# Put in a data frame dat <-data.frame(cluster_id, U, X, Y)# Compare different modeling approaches fit_lm <-coef(lm(Y ~ X +factor(cluster_id), data = dat))[2] # Fixed effects fit_lmer <-coef(lme4::lmer(Y ~ X + (1| cluster_id), data = dat))$cluster_id[1,2] # Random intercepts fit_fixest <- fixest::feols(Y ~ X | cluster_id, data = dat)$coefficients[["X"]] # Fixed effects (alternative) raw[[i]] <-data.frame(real_value =0.2,fixed_effects_lm = fit_lm,random_intercepts_lmer = fit_lmer,fixed_effects_fixest = fit_fixest )}
# Combine resultsresults <-rbindlist(raw)results[, id :=1:.N]results_long <-melt.data.table(results, id.vars =c("id", "real_value"))results_long[, deviance := value - real_value]# Calculate mean bias for each methodbias_summary <- results_long[, .(mean_bias =mean(deviance)), by = .(variable)]print(bias_summary)
Fixed effects models (both lm with cluster dummies and fixest) correctly estimate the causal effect with minimal bias
Random intercepts models show substantial bias, failing to adequately control for the cluster-level confounder
This demonstrates that when confounding occurs at the cluster level, random intercepts do not provide adequate control for confounding, while fixed effects do.
When to use random vs fixed rffects
Use random intercepts when:
You want to make inferences about the population of clusters (not just the observed clusters).
The clusters are a random sample from a larger population.
You’re primarily interested in individual-level effects.
The cluster-level variables are not confounders.
Use fixed effects when:
You want to control for all time-invariant cluster-level confounders.
You’re making inferences about the specific clusters in your data.
The cluster-level variables are potential confounders.
You want the most robust estimate of the exposure effect.
Conclusion
Random intercepts are a powerful tool for accounting for correlation within clusters, but they do not fix confounding when the confounder varies at the cluster level. When cluster-level confounding is a concern, fixed effects models provide more robust estimates of causal effects.
The choice between random and fixed effects should be guided by:
The causal structure of your data
Whether cluster-level variables are confounders
Your inferential goals (population vs. sample-specific inferences)
Understanding this distinction is crucial for proper epidemiological analysis and avoiding biased estimates of causal effects.